Introduction to Machine Learning
Machine Learning is everywhere. It used to be an exclusive tool used only by the giants in the industry.
Yet in our days it is used everywhere for many tasks.
From the simple tasks to the most advanced, from factories and the production line to IP based companies.
It is a must-have tool in any developer toolbox. If you want to start with, this is the course to take.
Overview
The course:
${\color{lime}\surd}$ Covers concepts in Machine Learning and their applications to data science tasks.
${\color{lime}\surd}$ Target developers who are required to participate in the development of an ML based application/algorithm.
${\color{lime}\surd}$ Designed to give a high-level overview of the field, the applications, and when and how to use it for System Engineers / Project Managers.
| Scientific Foundations | Linear algebra, optimization, probability, Python |
| Supervised Learning | Classification and regression |
| Unsupervised Learning | Density estimation, clustering, and dimensionality reduction |
Slide Samples

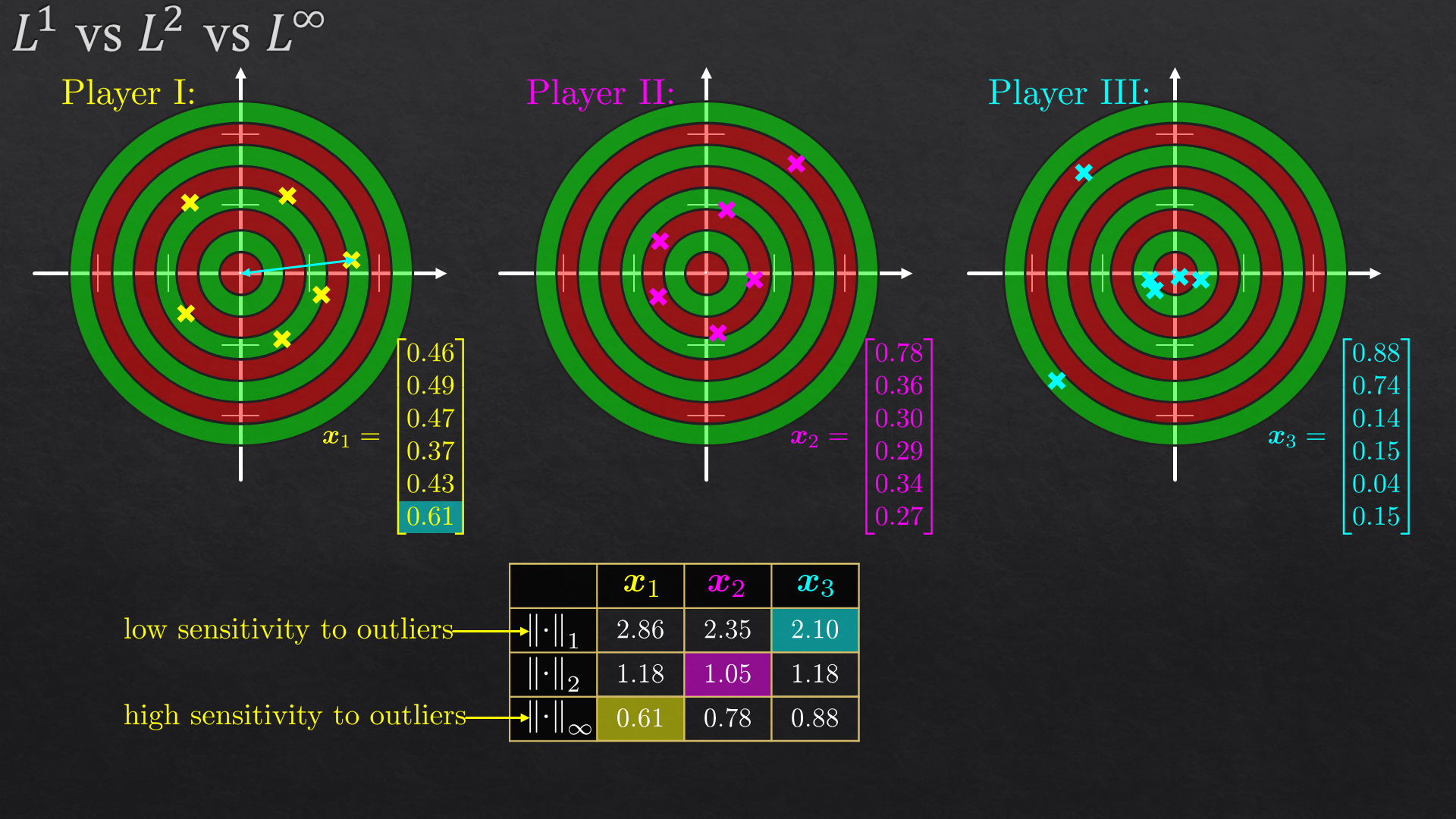
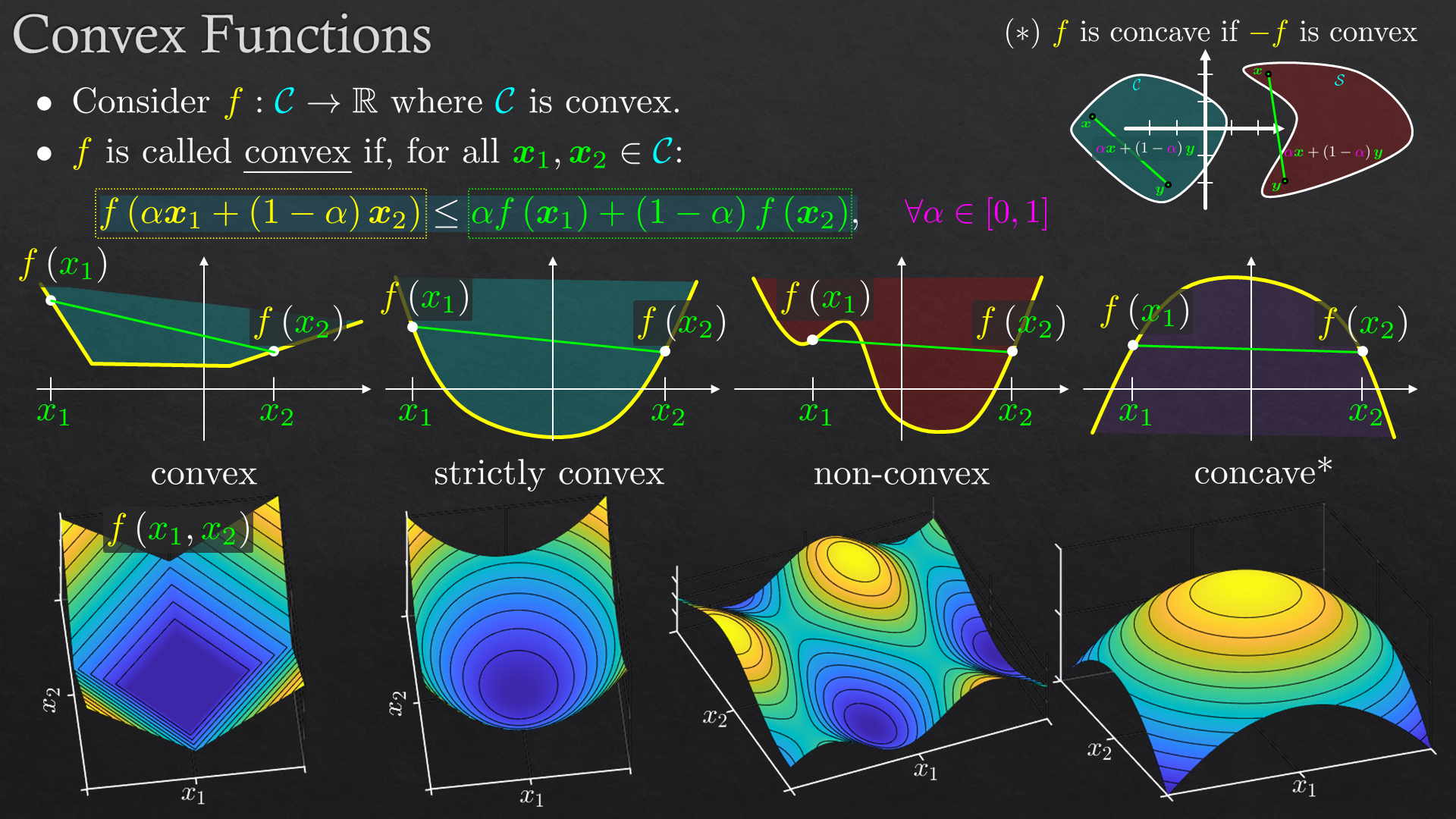
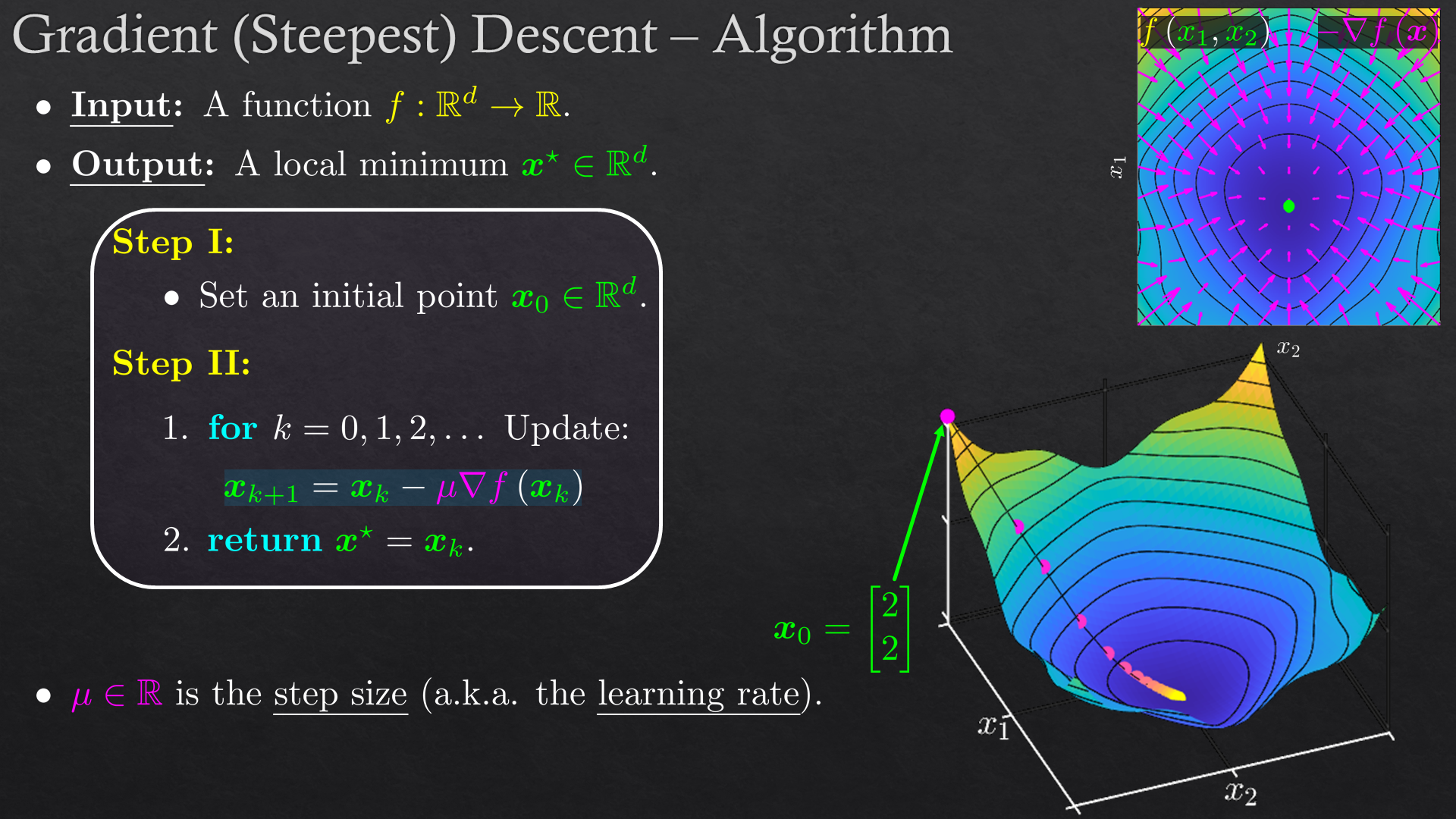
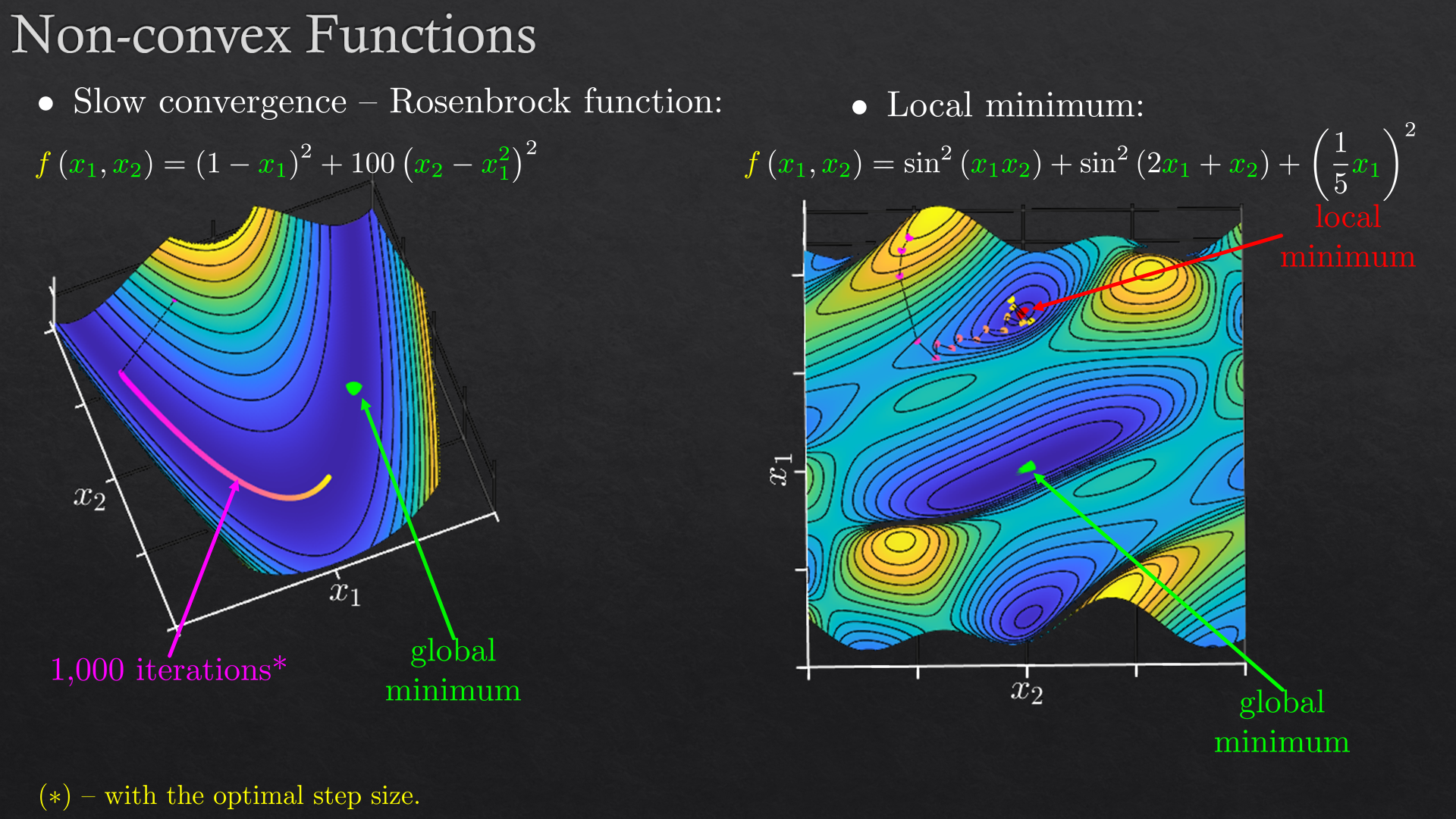


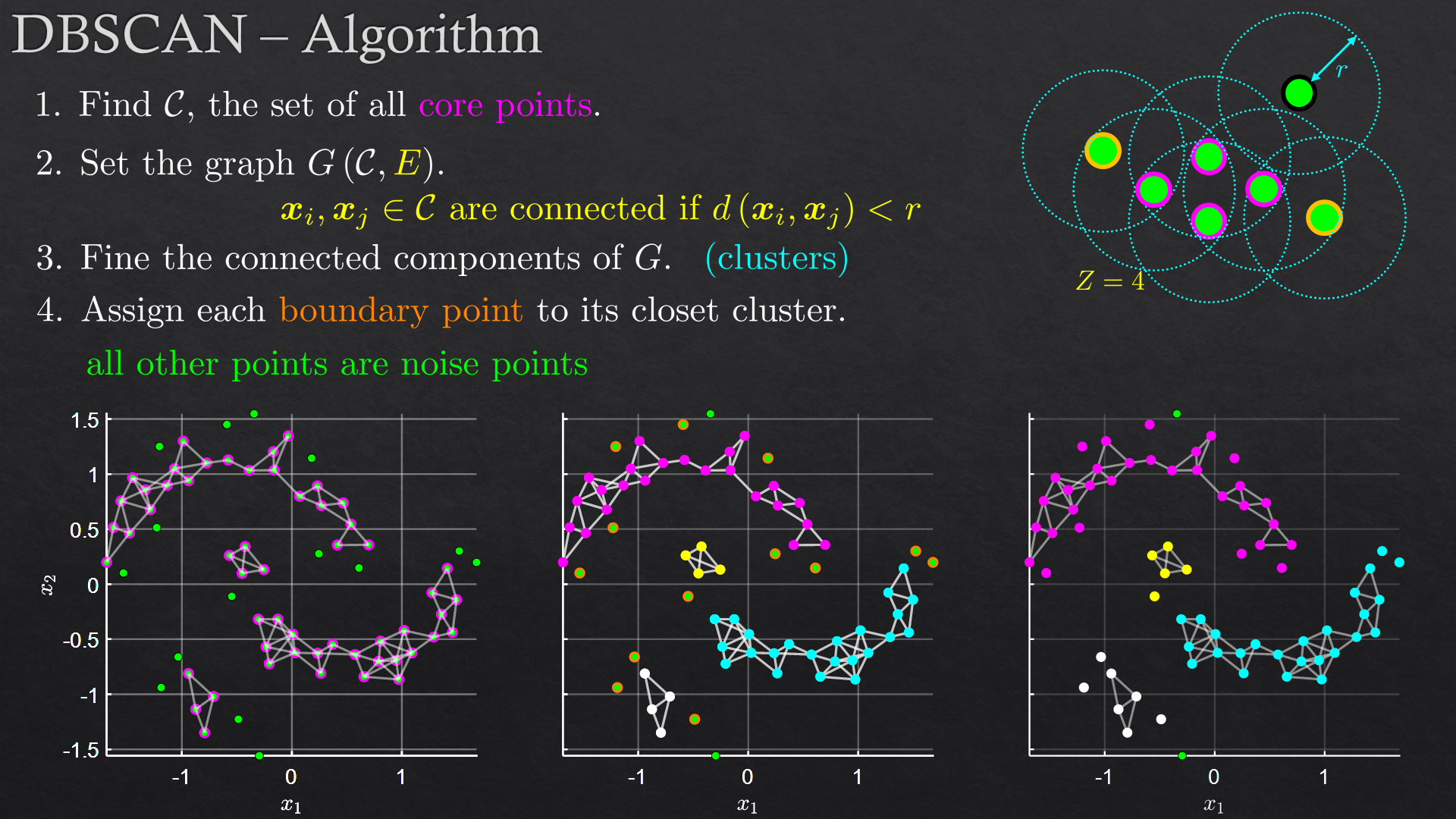
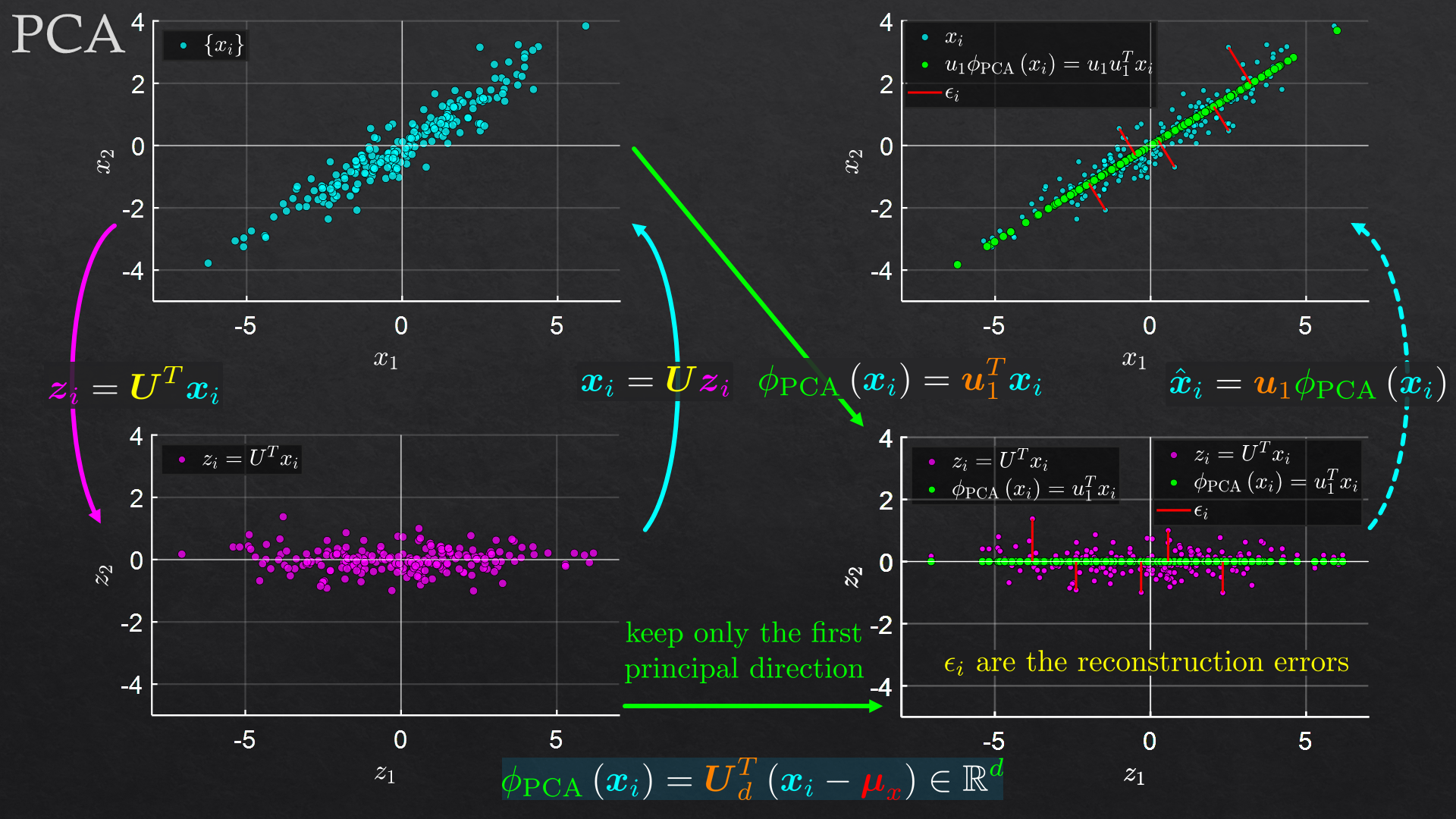

Goals
- The participants will be able to match the proper approach to a given problem.
- The participants will take into consideration the advantages\disadvantages of the learned methods.
- The participants will contribute to the development of ML pipeline: Processing raw data, implementing algorithms, and benchmark the results.
For comprehensive overview of the modern machine learning filed we recommend taking the Introduction to deep learning course right after this course.
Pre Built Syllabus
We have been given this course in various lengths, targeting different audiences. The final syllabus will be decided and customized according to audience, allowed time and other needs.
| Day | Subject | Details |
|---|---|---|
| 1 | Linear Algebra and Optimization | Vectors, norms, matrices, gradient descent |
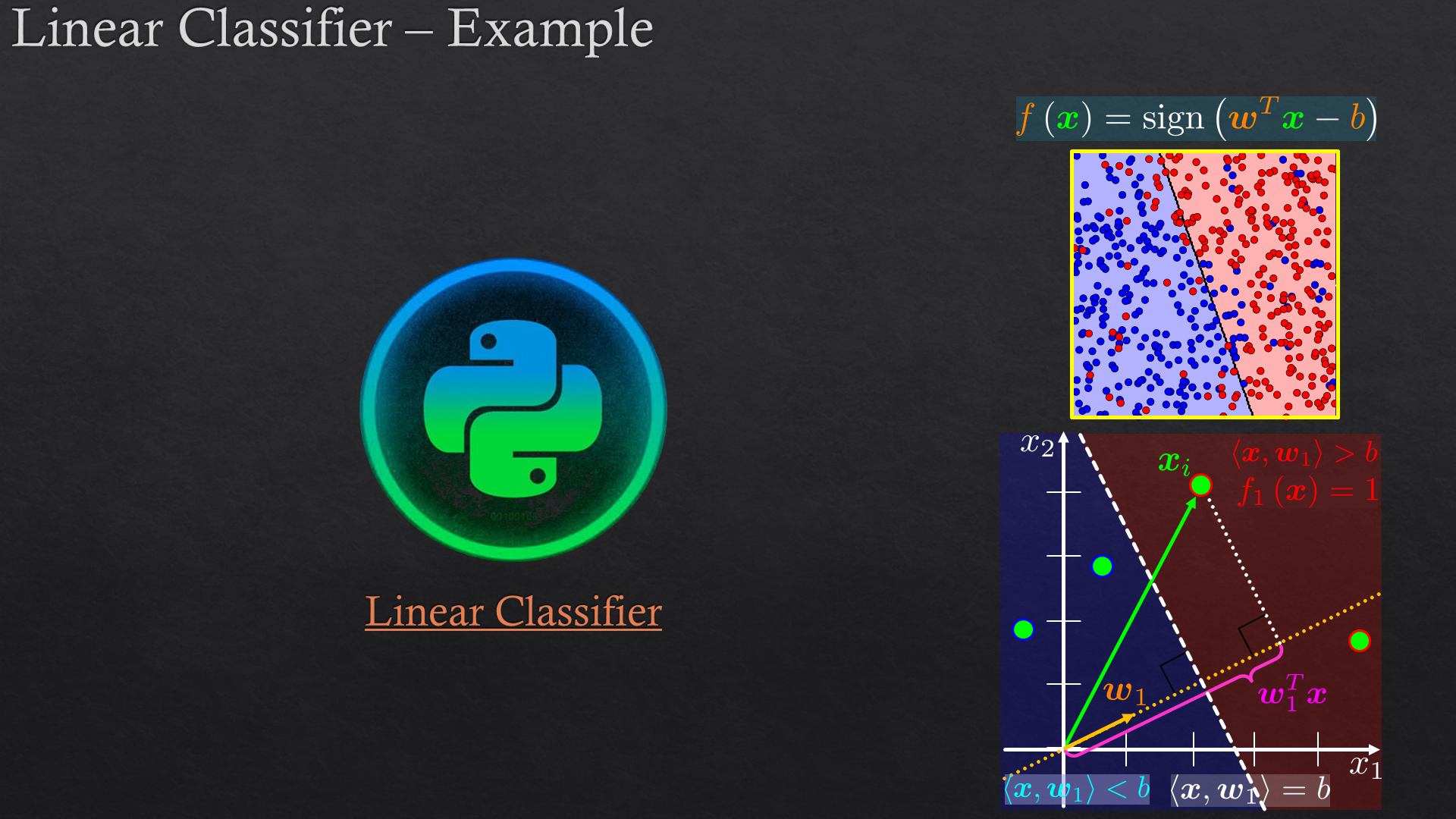
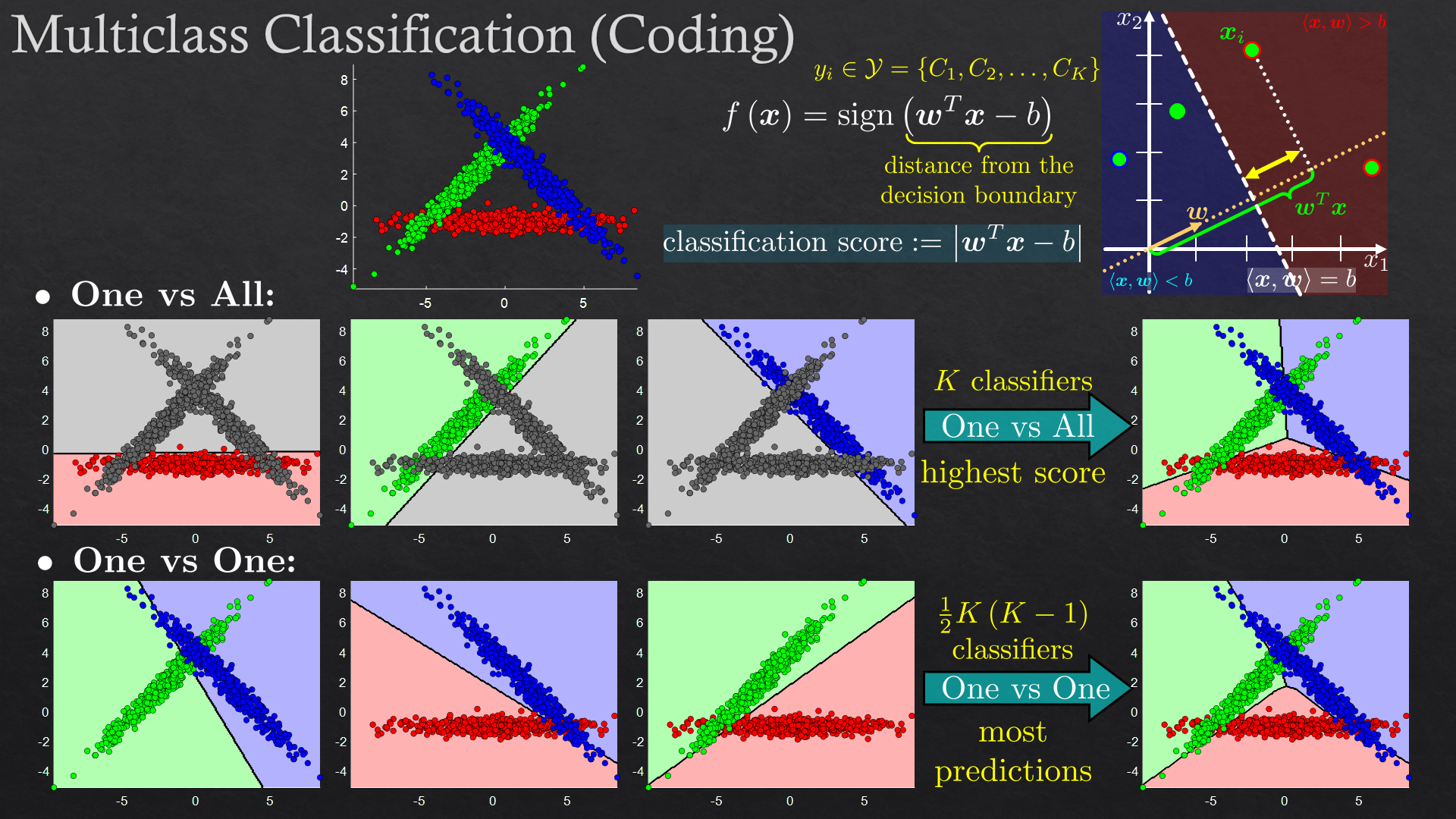
| Classification | Linear classification, support vector machine (SVM), K-nearest neighbors (K-NN) | |
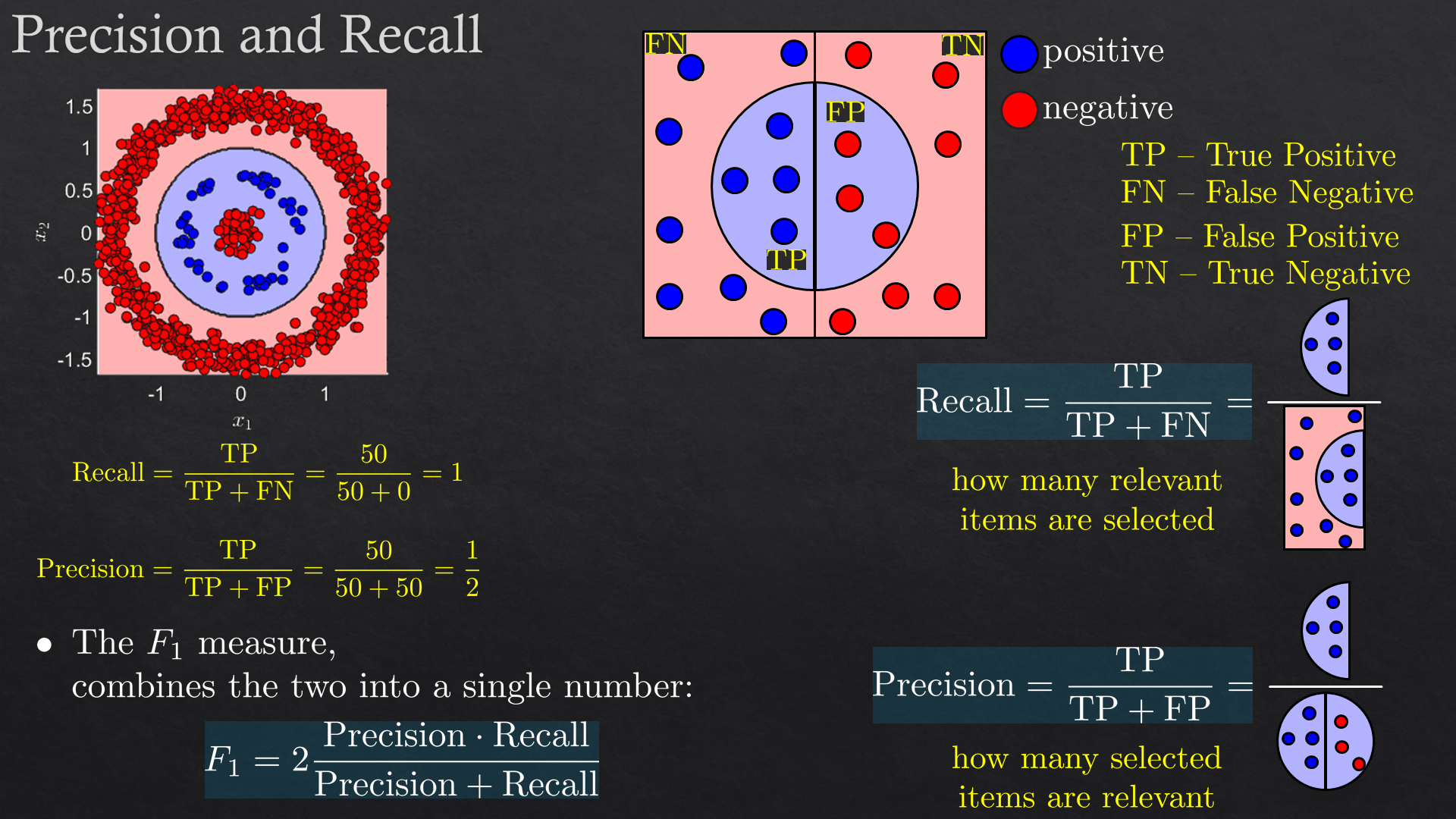
| Performance Evaluation | Overfit/underfit, cross validation, confusion matrix, loss (risk) function, performance quality (metric and scoring): accuracy, precision, recall, and f1 score, ROC and AUC | |
| Feature Engineering | Feature transform, the kernel trick, feature selection | |
| Exercise 0 | Classification and Python: numpy, scipy, pandas, matplotlib, and seabron | |
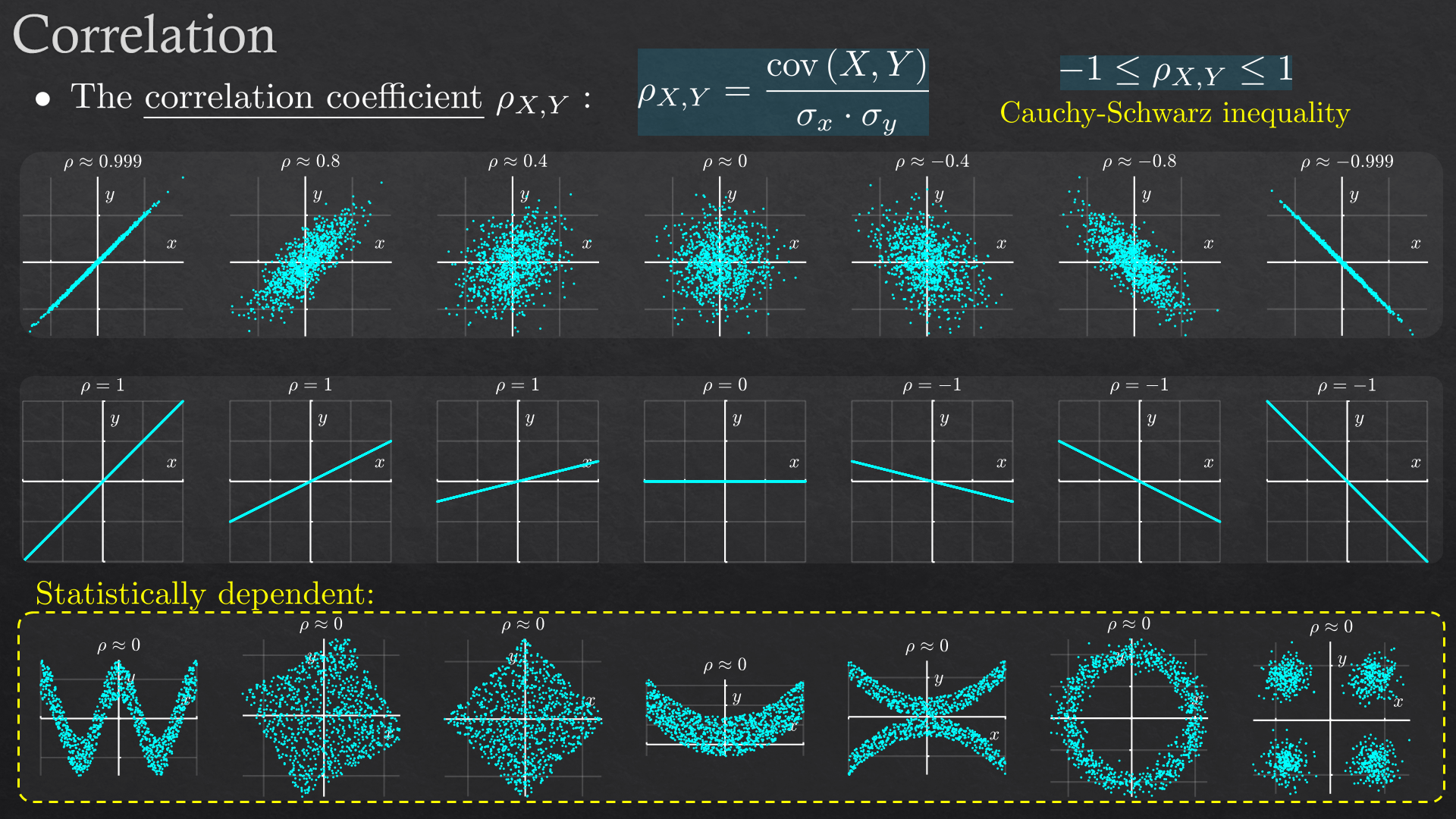
| 2 | Essential Probability | Random variable\vector (discrete\continuous), expected value and higher moments, statistical dependency and correlation, Bayes’ rule |
| Parametric Estimation | Maximum likelihood (ML) | |
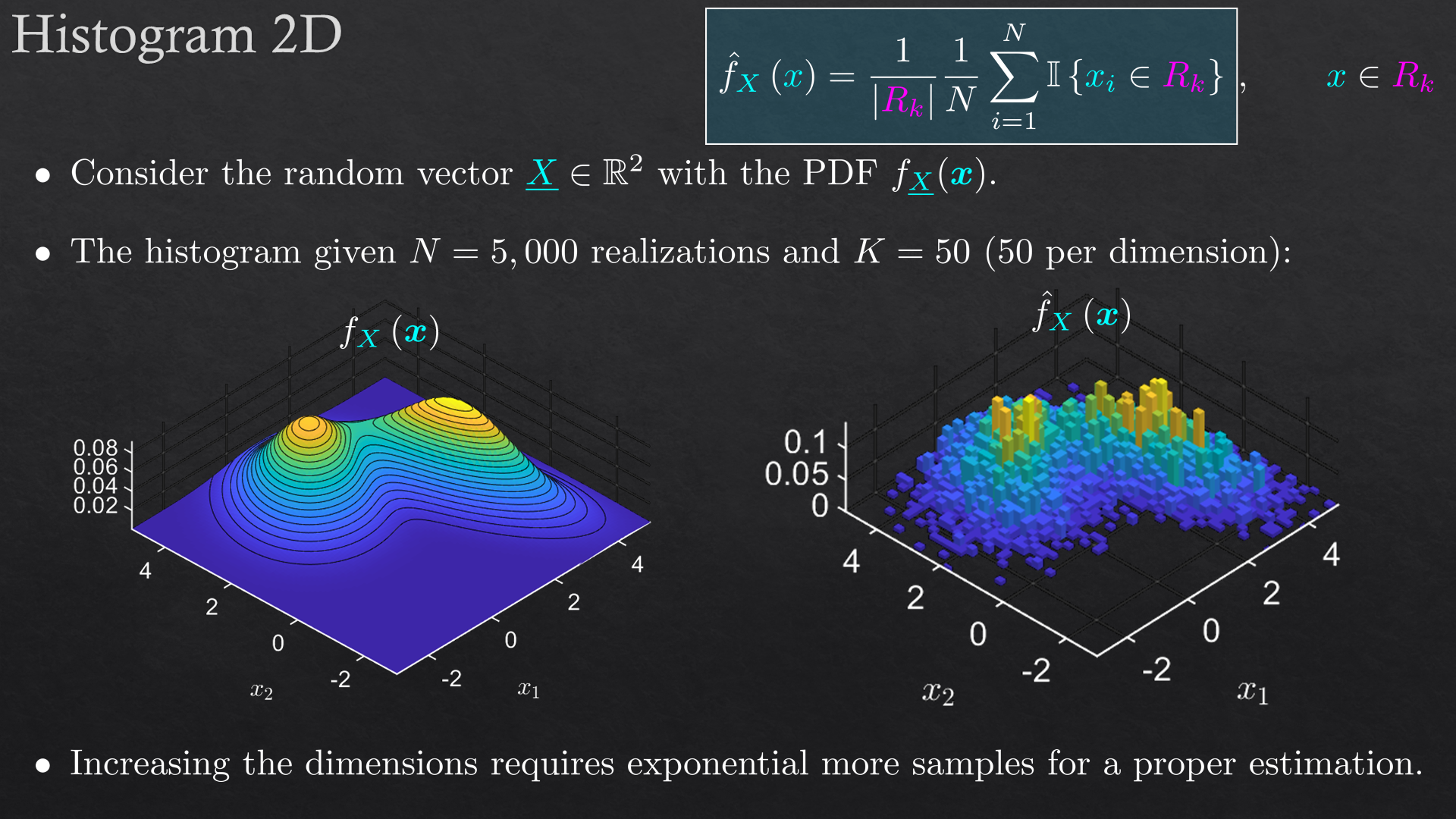
| Non Parametric Estimation | Histogram, kernel density estimation (KDE), order statistics | |
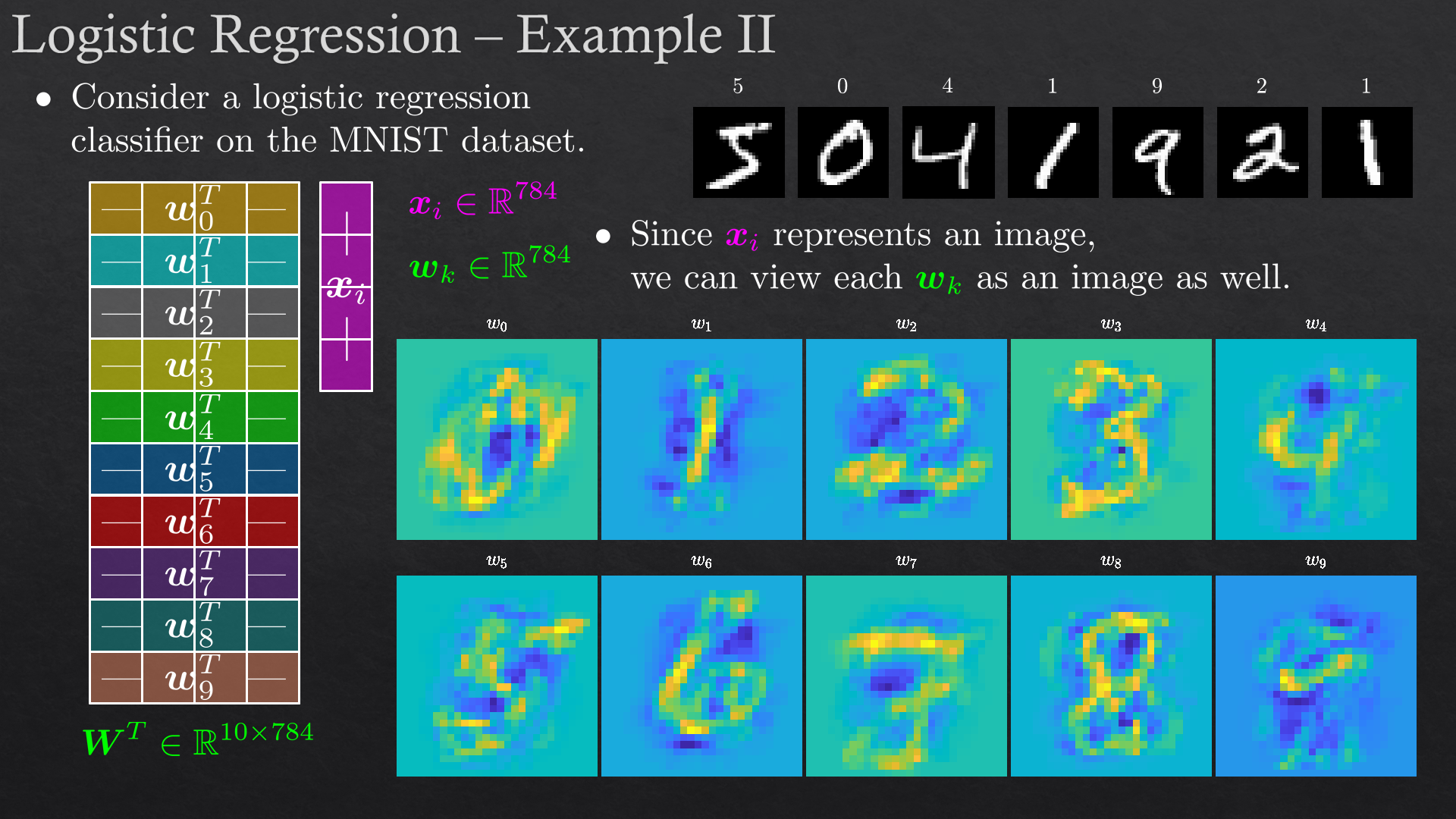
| Statistical Classification | Logistic regression, decision trees | |
| Exercise 1 | Classification, data analysis, visualization | |
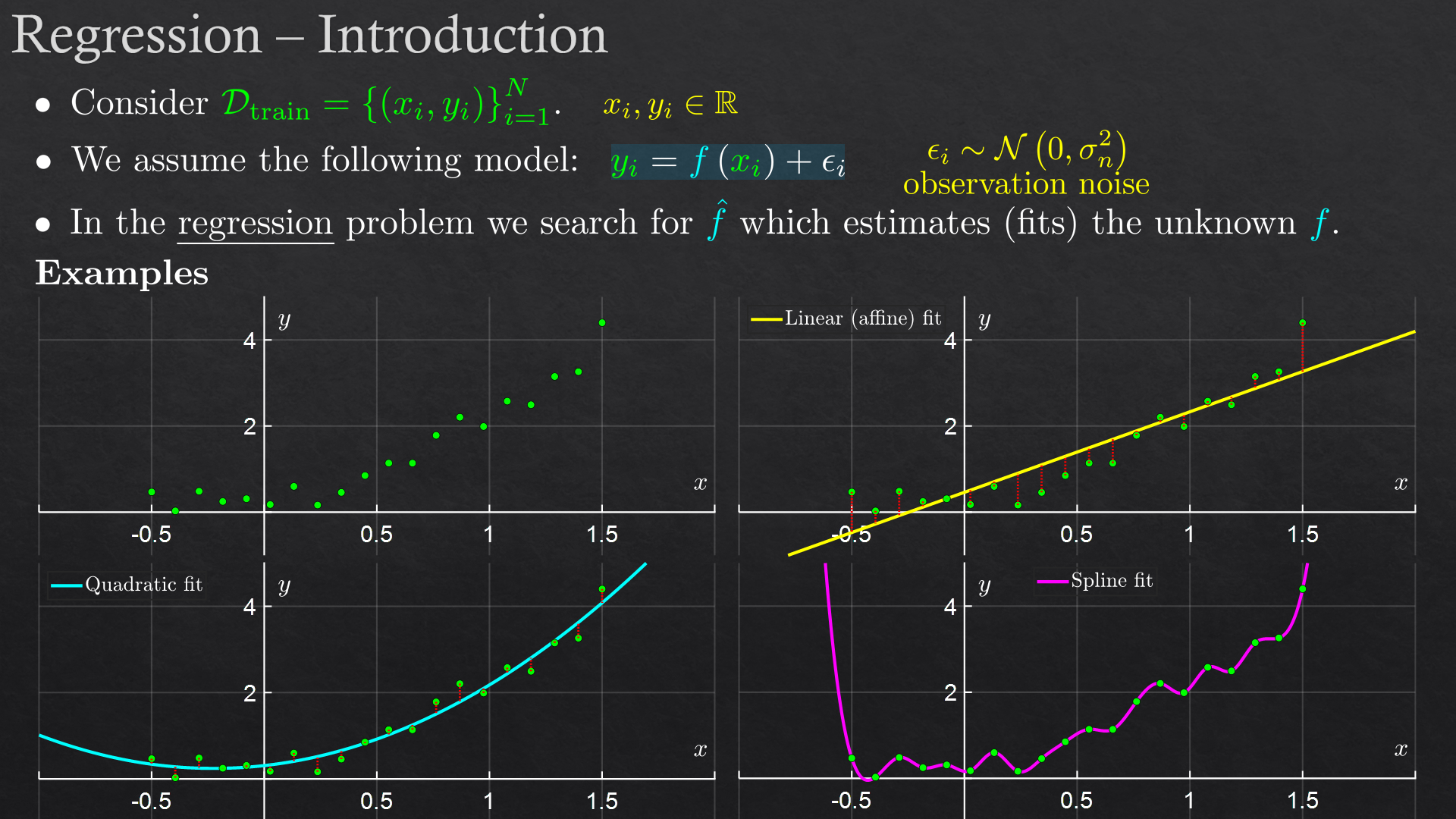
| 3 | Linear Regression | Linear least squares, polynomial fit and feature transform, R2 score |
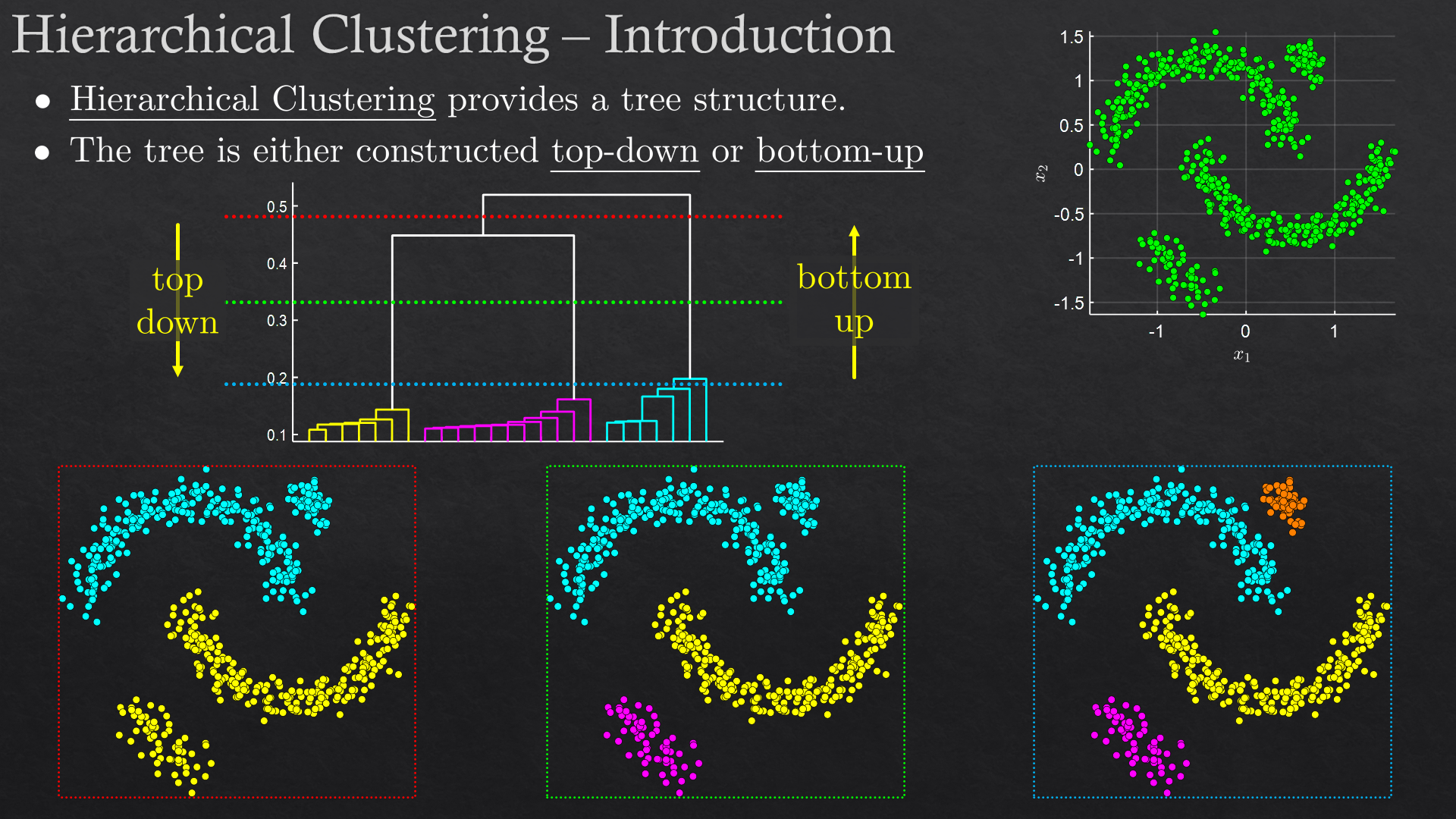
| Clustering | K-means, K-medoids, DBSCAN, hierarchical clustering (Ward’s method) | |
| Component Analysis | Principal component analysis (PCA) | |
| Non Linear Dimensionality Reduction | Multidimensional scaling (MDS), Isomaps, T-SNE | |
| Exercise 2 | Regression, data analysis, visualization |
In addition to the exercises in the syllabus, there are many more mini-exercises (within each topic).
Prerequisites
The course is an introductory course and as such, we try to minimize the prerequisites.
Moreover, we only assume a basic knowledge in each of the following:
- Linear Algebra.
- Basic Calculus.
- Basic Probability Theory.
- Basic Python and / or MATLAB knowledge.
In any case any of the prerequisites are not met, we can offer a half day sprint on: Linear Algebra, Calculus, Probability and Python.
We also offer advanced course in machine learning with emphasize on many advanced methods: Machine learning methods.